第一节
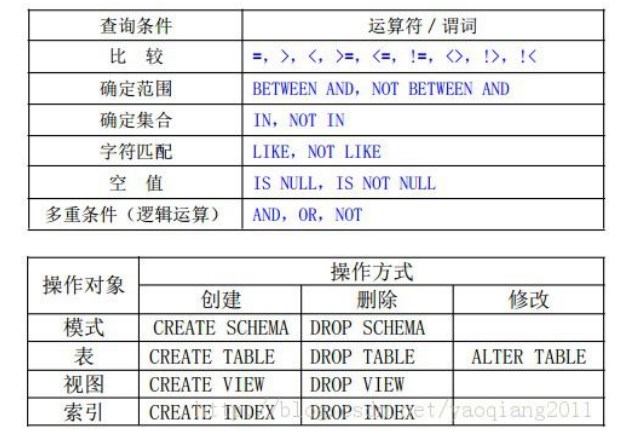
一、相关概念
1. Data:数据,是数据库中存储的基本对象,是描述事物的符号记录。
2. Database:数据库,是长期储存在计算机内、有组织的、可共享的大量数据的集
合。
3. DBMS:数据库管理系统,是位于用户与操作系统之间的一层数据管理软件,用于
科学地组织、存储和管理数据、高效地获取和维护数据。
4. DBS:数据库系统,指在计算机系统中引入数据库后的系统,一般由数据库、数据
库管理系统、应用系统、数据库管理员(DBA)构成。
5. 数据模型:是用来抽象、表示和处理现实世界中的数据和信息的工具,是对现实世
界的模拟,是数据库系统的核心和基础;其组成元素有数据结构、数据操作和完整性约束。
6. 概念模型:也称信息模型,是按用户的观点来对数据和信息建模,主要用于数据库
设计。
7. 逻辑模型:是按计算机系统的观点对数据建模,用于 DBMS 实现。
8. 物理模型:是对数据最底层的抽象,描述数据在系统内部的表示方式和存取方法,
在磁盘或磁带上的存储方式和存取方法,是面向计算机系统的。
9. 实体和属性:客观存在并可相互区别的事物称为实体。实体所具有的某一特性称为
属性。
10.E-R 图:即实体-关系图,用于描述现实世界的事物及其相互关系,是数据库概念
模型设计的主要工具。
11.关系模式:从用户观点看,关系模式是由一组关系组成,每个关系的数据结构是
一张规范化的二维表。
12.型/值:型是对某一类数据的结构和属性的说明;值是型的一个具体赋值,是型的
实例。
13.数据库模式:是对数据库中全体数据的逻辑结构(数据项的名字、类型、取值范
围等)和特征(数据之间的联系以及数据有关的安全性、完整性要求)的描述。
14.数据库的三级系统结构:外模式、模式和内模式。
15.数据库内模式:又称为存储模式,是对数据库物理结构和存储方式的描述,是数
据在数据库内部的表示方式。一个数据库只有一个内模式。
16.数据库外模式:又称为子模式或用户模式,它是数据库用户能够看见和使用的局
部数据的逻辑结构和特征的描述,是数据库用户的数据视图。通常是模式的子集。一个数据
库可有多个外模式。
17.数据库的二级映像:外模式/模式映像、模式/内模式映像。
二、重点知识点
1. 数据库系统由数据库、数据库管理系统、应用系统和数据库管理员构成。
2. 数据模型的组成要素是:数据结构、数据操作、完整性约束条件。
3. 实体型之间的联系分为一对一、一对多和多对多三种类型。
4. 常见的数据模型包括:关系、层次、网状、面向对象、对象关系映射等几种。
5. 关系模型的完整性约束包括:实体完整性、参照完整性和用户定义完整性。
6. 阐述数据库三级模式、二级映象的含义及作用。
数据库三级模式反映的是数据的三个抽象层次: 模式是对数据库中全体数据的逻辑
结构和特征的描述。内模式又称为存储模式,是对数据库物理结构和存储方式的描述。外模
式又称为子模式或用户模式,是对特定数据库用户相关的局部数据的逻辑结构和特征的描
述。
数据库三级模式通过二级映象在 DBMS 内部实现这三个抽象层次的联系和转换。外
模式面向应用程序, 通过外模式/模式映象与逻辑模式建立联系, 实现数据的逻辑独立
性。 模式/内模式映象建立模式与内模式之间的一对一映射, 实现数据的物理独立性。
第二节
一、相关概念
1. 主键: 能够唯一地标识一个元组的属性或属性组称为关系的键或候选键。 若一个
关系有多个候选键则可选其一作为主键(Primary key)。
2. 外键:如果一个关系的一个或一组属性引用(参照)了另一个关系的主键,则称这个
或这组属性为外码或外键(Foreign key)。
3. 关系数据库: 依照关系模型建立的数据库称为关系数据库。 它是在某个应用领域
的所有关系的集合。
4. 关系模式: 简单地说,关系模式就是对关系的型的定义, 包括关系的属性构成、
各属性的数据类型、 属性间的依赖、 元组语义及完整性约束等。 关系是关系模式在某一时
刻的状态或内容, 关系模型是型, 关系是值, 关系模型是静态的、 稳定的, 而关系是动
态的、随时间不断变化的,因为关系操作在不断地更新着数据库中的数据。
5. . 实体完整性:用于标识实体的唯一性。它要求基本关系必须要有一个能够标识元
组唯一性的主键,主键不能为空,也不可取重复值。
6. 参照完整性:用于维护实体之间的引用关系。它要求一个关系的外键要么为空,要
么取与被参照关系对应的主键值,即外键值必须是主键中已存在的值。
7. 用户定义的完整性:就是针对某一具体应用的数据必须满足的语义约束。包括非
空、 唯一和布尔条件约束三种情况。
二、重要知识点
1. 关系数据库语言分为关系代数、关系演算和结构化查询语言三大类。
2. 关系的 5 种基本操作是选择、投影、并、差、笛卡尔积。
3.关系模式是对关系的描述,五元组形式化表示为:R(U,D,DOM,F),其中
R —— 关系名
U —— 组成该关系的属性名集合
D —— 属性组 U 中属性所来自的域
DOM —— 属性向域的映象集合
F —— 属性间的数据依赖关系集合
4.笛卡尔乘积,选择和投影运算如下

第三节
一、相关概念
1. SQL:结构化查询语言的简称,是关系数据库的标准语言。SQL 是一种通用的、功
能极强的关系数据库语言, 是对关系数据存取的标准接口, 也是不同数据库系统之间互操
作的基础。集数据查询、数据操作、数据定义、和数据控制功能于一体。
2. 数据定义:数据定义功能包括模式定义、表定义、视图和索引的定义。
3. 嵌套查询:指将一个查询块嵌套在另一个查询块的 WHERE 子句或 HAVING 短语
的条件中的查询。
二、重要知识点
1. SQL 数据定义语句的操作对象有:模式、表、视图和索引。
2. SQL 数据定义语句的命令动词是:CREATE、DROP 和 ALTER。
3. RDBMS 中索引一般采用 B+树或 HASH 来实现。
4. 索引可以分为唯一索引、非唯一索引和聚簇索引三种类型
6.SQL 创建表语句的一般格式为
CREATE TABLE <表名>
( <列名> <数据类型>[ <列级完整性约束> ]
[,<列名> <数据类型>[ <列级完整性约束>] ] …
[,<表级完整性约束> ] ) ;
其中<数据类型>可以是数据库系统支持的各种数据类型,包括长度和精度。
列级完整性约束为针对单个列(本列)的完整性约束, 包
括 PRIMARY KEY、 REFERENCES 表名(列名)、UNIQUE、NOT NULL 等。
表级完整性约束可以是基于表中多列的约束,包括 PRIMARY KEY ( 列名列表) 、
FOREIGN KEY REFERENCES 表名(列名) 等。
7. SQL 创建索引语句的一般格式为
CREATE [UNIQUE] [CLUSTER] INDEX <索引名>
ON <表名> (<列名列表> ) ;
其中 UNIQUE:表示创建唯一索引,缺省为非唯一索引;
CLUSTER:表示创建聚簇索引,缺省为非聚簇索引;
<列名列表>:一个或逗号分隔的多个列名,每个列名后可跟 ASC 或 DESC,表示
升/降序,缺省为升序。多列时则按为多级排序。
8. SQL 查询语句的一般格式为
SELECT [ALL|DISTINCT] <算术表达式列表> FROM <表名或视图名列表>
[ WHERE <条件表达式 1> ]
[ GROUP BY <属性列表 1> [ HAVING <条件表达式 2 > ] ]
[ ORDER BY <属性列表 2> [ ASC|DESC ] ] ;
其中
ALL/DISTINCT: 缺省为 ALL, 即列出所有查询结果记录, 包括重复记
录。 DISTINCT 则对重复记录只列出一条。
算术表达式列表:一个或多个逗号分隔的算术表达式,表达式由常量(包括数字和字符
串)、列名、函数和算术运算符构成。每个表达式后还可跟别名。也可用 *代表查询表中的
所有列。
<表名或视图名列表>: 一个或多个逗号分隔的表或视图名。 表或视图名后可跟别
名。
条件表达式 1:包含关系或逻辑运算符的表达式,代表查询条件。
条件表达式 2:包含关系或逻辑运算符的表达式,代表分组条件。
<属性列表 1>:一个或逗号分隔的多个列名。
<属性列表 2>: 一个或逗号分隔的多个列名, 每个列名后可
跟 ASC 或 DESC, 表示升/降序,缺省为升序。
关于 SQL 语句的知识这里先作如上简略介绍,具体写法下次将专门拿出一篇来叙述。
第四节
一、相关概念和知识
1.触发器是用户定义在基本表上的一类由事件驱动的特殊过程。由服务器自动激活,能
执行更为复杂的检查和操作,具有更精细和更强大的数据控制能力。使
用 CREATE TRIGGER 命令建立触发器。
2.计算机系统存在技术安全、管理安全和政策法律三类安全性问题。
3. TCSEC/TDI 标准由安全策略、责任、保证和文档四个方面内容构成。
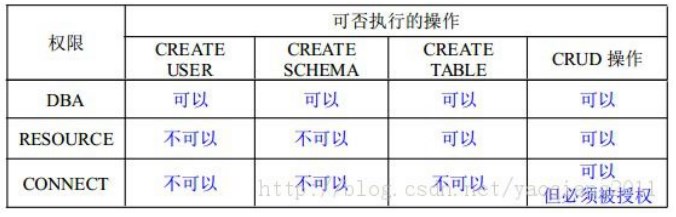
4. 常用存取控制方法包括自主存取控制(DAC)和强制存取控制(MAC)两种。
5. 自主存取控制(DAC)的 SQL 语句包括 GRANT 和 REVOKE 两个。 用户权限由数
据对象和操作类型两部分构成。
6. 常见 SQL 自主权限控制命令和例子。
1) 把对 Student 和 Course 表的全部权限授予所有用户。
GRANT ALL PRIVILIGES ON TABLE Student,Course TO PUBLIC ;
2) 把对 Student 表的查询权和姓名修改权授予用户 U4。
GRANT SELECT,UPDATE(Sname) ON TABLE Student TO U4 ;
3) 把对 SC 表的插入权限授予 U5 用户,并允许他传播该权限。
GRANT INSERT ON TABLE SC TO U5 WITH GRANT OPTION ;
4) 把用户 U5 对 SC 表的 INSERT 权限收回,同时收回被他传播出去的授权。
REVOKE INSERT ON TABLE SC FROM U5 CASCADE ;
5) 创建一个角色 R1,并使其对 Student 表具有数据查询和更新权限。
CREATE ROLE R1;
GRANT SELECT,UPDATE ON TABLE Student TO R1;
6) 对修改 Student 表结构的操作进行审计。
一、相关概念和知识点
1.数据依赖:反映一个关系内部属性与属性之间的约束关系,是现实世界属性间相互
联系的抽象,属于数据内在的性质和语义的体现。
2. 规范化理论:是用来设计良好的关系模式的基本理论。它通过分解关系模式来消除
其中不合适的数据依赖,以解决插入异常、删除异常、更新异常和数据冗余问题。
3. 函数依赖:简单地说,对于关系模式的两个属性子集 X 和 Y,若 X 的任一取值能唯
一确定 Y 的值,则称 Y 函数依赖于 X,记作 X→Y。
4. 非平凡函数依赖:对于关系模式的两个属性子集 X 和 Y,如果 X→Y,但 Y!⊆X,则
称 X→Y 为非平凡函数依赖;如果 X→Y,但 Y⊆X,则称 X→Y 为非平凡函数依赖。
5. 完全函数依赖:对于关系模式的两个属性子集 X 和 Y,如果 X→Y,并且对于 X 的
任何一个真子集 X',都没有 X'→Y,则称 Y 对 X 完全函数依赖。
6. 范式:指符合某一种级别的关系模式的集合。在设计关系数据库时,根据满足依赖
关系要求的不同定义为不同的范式。
7. 规范化:指将一个低一级范式的关系模式,通过模式分解转换为若干个高一级范式
的关系模式的集合的过程。
8. 1NF:若关系模式的所有属性都是不可分的基本数据项,则该关系模式属于 1NF。
9. 2NF:1NF 关系模式如果同时满足每一个非主属性完全函数依赖于码,则该关系模
式属于 2NF。
10. 3NF:若关系模式的每一个非主属性既不部分依赖于码也不传递依赖于码,则该
关系模式属于 3NF。
11. BCNF:若一个关系模式的每一个决定因素都包含码,则该关系模式属于 BCNF。
12. 数据库设计:是指对于一个给定的应用环境,构造优化的数据库逻辑模式和物理
结构,并据此建立数据库及其应用系统,使之能够有效地存储和管理数据,满足各种用户的
应用需求,包括信息管理要求和数据操作要求。
13. 数据库设计的 6 个基本步骤:需求分析,概念结构设计,逻辑结构设计,物理结
构设计,数据库实施,数据库运行和维护。
14. 概念结构设计:指将需求分析得到的用户需求抽象为信息结构即概念模型的过程。
也就是通过对用户需求进行综合、归纳与抽象,形成一个独立于具体 DBMS 的概念模型。
15. 逻辑结构设计:将概念结构模型(基本 E-R 图)转换为某个 DBMS 产品所支持的
数据模型相符合的逻辑结构,并对其进行优化。
16. 物理结构设计:指为一个给定的逻辑数据模型选取一个最适合应用环境的物理结
构的过程。包括设计数据库的存储结构与存取方法。
17. 抽象:指对实际的人、物、事和概念进行人为处理,抽取所关心的共同特性,忽
略非本质的细节,并把这些特性用各种概念精确地加以描述,这些概念组成了某种模型。
18. 数据库设计必须遵循结构设计和行为设计相结合的原则。
19. 数据字典主要包括数据项、数据结构、数据流、数据存储和处理过程五个部分。
20. 三种常用抽象方法是分类、聚集和概括。
21. 局部 E-R 图之间的冲突主要表现在属性冲突、命名冲突和结构冲突三个方面。
22. 数据库常用的存取方法包括索引方法、聚簇方法和 HASH 方法三种。
23. 确定数据存放位置和存储结构需要考虑的因素主要有: 存取时间、 存储空间利
用率和维护代价等。
二、细说数据库三范式
2.1 第一范式(1NF)无重复的列
第一范式(1NF)中数据库表的每一列都是不可分割的基本数据项
同一列中不能有多个值
即实体中的某个属性不能有多个值或者不能有重复的属性。
简而言之,第一范式就是无重复的列。
在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一
范式(1NF)的数据库就不是关系数据库。
2.2 第二范式(2NF)属性完全依赖于主键[消除部分子函数依赖]
满足第二范式(2NF)必须先满足第一范式(1NF)。
第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。
为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在
仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出
来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上
一个列,以存储各个实例的惟一标识。简而言之,第二范式就是属性完全依赖于主键。
2.3 第三范式(3NF)属性不依赖于其它非主属性[消除传递依赖]
满足第三范式(3NF)必须先满足第二范式(2NF)。
简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主
关键字信息。
例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门
简介等信息。那么在的员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部
门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应
该构建它,否则就会有大量的数据冗余。简而言之,第三范式就是属性不依赖于其它非主属
性。
2.4 具体实例剖析
下面列举一个学校的学生系统的实例,以示几个范式的应用。
在设计数据库表结构之前,我们先确定一下要设计的内容包括那些。学号、学生姓名、
年龄、性别、课程、课程学分、系别、学科成绩,系办地址、系办电话等信息。为了简单我
们暂时只考虑这些字段信息。我们对于这些信息,说关心的问题有如下几个方面。
1)学生有那些基本信息
2)学生选了那些课,成绩是什么
3)每个课的学分是多少
4)学生属于那个系,系的基本信息是什么。
首先第一范式(1NF):数据库表中的字段都是单一属性的,不可再分。这个单一属
性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。在当前的任何关系数据
库管理系统(DBMS)中,不允许你把数据库表的一列再分成二列或多列,因此做出的都是
符合第一范式的数据库。
我们再考虑第二范式,把所有这些信息放到一个表中(学号,学生姓名、年龄、性别、
课程、课程学分、系别、学科成绩,系办地址、系办电话)下面存在如下的依赖关系。
1)(学号)→ (姓名, 年龄,性别,系别,系办地址、系办电话)
2) (课程名称) → (学分)
3)(学号,课程)→ (学科成绩)
根据依赖关系我们可以把选课关系表 SelectCourse 改为如下三个表:
学生:Student(学号,姓名, 年龄,性别,系别,系办地址、系办电话);
课程:Course(课程名称, 学分);
选课关系:SelectCourse(学号, 课程名称, 成绩)。
事实上,对照第二范式的要求,这就是满足第二范式的数据库表,若不满足第二范式,
会产生如下问题
数据冗余: 同一门课程由 n 个学生选修,"学分"就重复 n-1 次;同一个学生选修了 m 门课
程,姓名和年龄就重复了 m-1 次。
更新异常: 1)若调整了某门课程的学分,数据表中所有行的"学分"值都要更新,否则会出
现同一门课程学分不同的情况。
2)假设要开设一门新的课程,暂时还没有人选修。这样,由于还没有"学号" 关键字,课程名称和学分也无法记录入数据库。
删除异常 : 假设一批学生已经完成课程的选修,这些选修记录就应该从数据库表中删除。
但是,与此同时,课程名称和学分信息也被删除了。很显然,这也会导致插入异常。
我们再考虑如何将其改成满足第三范式的数据库表,接着看上面的学生表 Student(学
号,姓名, 年龄,性别,系别,系办地址、系办电话),关键字为单一关键字"学号",因为存
在如下决定关系:
(学号)→ (姓名, 年龄,性别,系别,系办地址、系办电话)
但是还存在下面的决定关系
(学号) → (所在学院)→(学院地点, 学院电话)
即存在非关键字段"学院地点"、"学院电话"对关键字段"学号"的传递函数依赖。
它也会存在数据冗余、更新异常、插入异常和删除异常的情况(这里就不具体分析了,
参照第二范式中的分析)。根据第三范式把学生关系表分为如下两个表就可以满足第三范式
了:
学生:(学号, 姓名, 年龄, 性别,系别);
系别:(系别, 系办地址、系办电话)。
这一部分是 C/C++程序员在面试的时候会被问到的一些题目的汇总。来源于基本笔试面
试书籍,可能有一部分题比较老,但是这也算是基础